GPT-4预训练数据量有多少TB?揭示GPT-3.5和GPT-4区别及其训练成本
大家好!今天我们来揭秘一个超级热门的话题——GPT-4的预训练数据量是多少TB?以及GPT-3.5和GPT-4的区别,还有GPT-4的训练成本。让我们一起来了解一下这些高科技背后的秘密吧!
什么是GPT-4?
GPT-4是OpenAI推出的最新一代生成式预训练模型。简单来说,它就像一个超级聪明的机器人,可以理解和生成文本。你可以拿它来写文章、编程、甚至进行对话,非常厉害!而GPT-4比之前的版本更加强大和智能。那么它到底是怎么变得如此强大的呢?
GPT-4预训练数据量有多少TB?
为了让GPT-4变得聪明,它需要大量的数据来进行训练。根据一些信息来源,GPT-4使用的数据量大约在9万亿个tokens!这样大量的数据转换成我们平时用的存储单位,大约相当于45 TB。要知道,45TB的数据可以装下超过四千五百万本英文书籍!是不是很惊人?
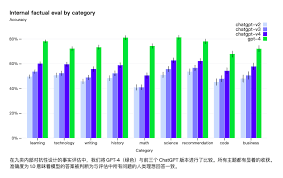
GPT-3.5和GPT-4的区别
那么,GPT-3.5和GPT-4有什么区别呢?让我们来看看:
- 参数量:GPT-3.5拥有1750亿参数,而GPT-4的参数量高达1.8万亿!是前者的十倍左右。
- 模型结构:GPT-4采用了更复杂的混合专家(MoE)结构,使得它在处理复杂任务时更加高效。
- 训练数据:GPT-4使用了更多、更高质量的数据来训练,包括大约9万亿个tokens。
- 能力:得益于更多的参数和更复杂的结构,GPT-4在生成文本的质量和多样性方面有显著提升。
GPT-4的训练成本
用这么多数据训练一个模型需要耗费大量的资源。有人估算训练一次GPT-4的成本大约是6300万美元。这可是非常昂贵的,但是它带来的智能水平是无价的!
实用建议
- 如果你是开发者,利用GPT-4进行开发时要注意它的内存和算力需求,因为它需要庞大的计算资源。
- 用户在使用GPT-4时,可以多给它提供清晰的上下文信息,它会给你更准确的回答。
- 如果你只是普通用户,好奇心驱动的话,可以多尝试和GPT-4对话,发现它的不同回答风格。
常见问题解答
GPT-4为什么需要这么多数据?
因为要让模型变得更智能,需要让它“阅读”大量的文本,学习各种语言模式和知识。
GPT-4能做什么?
GPT-4可以用来写文章、翻译、编程、对话等,几乎所有需要语言理解和生成的任务它都能胜任。
使用GPT-4会不会很贵?
虽然训练成本很高,但是使用GPT-4的服务相对来说还是比较经济的,具体价格取决于服务商。
总结
通过这篇文章,我们简要介绍了GPT-4预训练数据量有多少TB,以及GPT-3.5和GPT-4的区别,还揭示了GPT-4的训练成本。没错,GPT-4的诞生离不开大量的数据和先进的技术,它的强大能力为我们带来了无限的可能性。对于开发者和用户而言,了解这些信息能帮助我们更好地使用和开发基于GPT-4的应用。
如果你对GPT-4感兴趣,可以尝试使用它来体验一下,它将会是你探索AI世界的好伙伴!