如何在本地部署和运行ChatGPT:详细指南及常见问题解答
如何在本地部署和运行ChatGPT:详细指南及常见问题解答
想知道如何在您的电脑上部署和运行ChatGPT吗?这是一个很棒的想法!通过本地部署,您可以充分控制数据和使用,更好地保护隐私。在这篇文章中,我们将带您了解从部署准备到运行测试的一整套步骤,还会解答一些常见问题。让我们一起开始吧!
为什么要在本地部署ChatGPT?
本地部署ChatGPT有很多好处。首先,它可以更好地保护您的数据隐私。其次,您不需要依赖外部服务器,确保全天候可用。最后,您可以根据需要进行定制,实现更多功能。
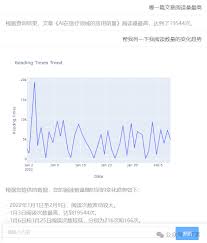
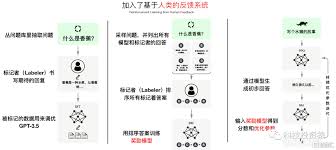
[插图: 本地部署的优势]
开始部署ChatGPT之前的准备工作
在开始本地部署ChatGPT之前,有些准备工作是必不可少的:
- 硬件要求:一台具备现代GPU的计算机,如NVIDIA的GeForce GTX 1080或更高版本。
- 软件要求:安装Python,建议使用3.6或以上版本。
- 依赖库:确保安装必要的依赖库,如PyTorch、transformers等。
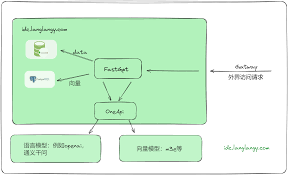
[插图: 准备工作的各个步骤]
详细部署步骤指南
1. 安装Python
首先,您需要在计算机上安装Python。如果您的电脑还没有安装,请前往Python官网下载安装包并进行安装。
https://www.python.org2. 下载ChatGPT模型
接下来,您需要下载ChatGPT的预训练模型。您可以从OpenAI的官方资源获取这些模型。
https://github.com/openai/gpt-33. 安装依赖库
确保您已安装所需的依赖库,如pytorch、transformers等,这些库是运行ChatGPT所必需的。
pip install torch transformers4. 配置和运行环境
创建一个虚拟环境,然后激活它以保持项目的依赖关系清晰。接下来,配置环境变量和其他必要的设置。
python -m venv chatgpt-env
source chatgpt-env/bin/activate
5. 测试运行
所有设置完成后,可以启动ChatGPT进行测试。确保一切都正常工作,以便可以开始实际使用。
python test_chatgpt.py[插图: 部署步骤示意图]
ChatGPT本地部署的实用建议
- 定期更新模型: 确保您使用的是最新版本的模型,以获得最佳性能。
- 优化性能: 根据硬件情况,优化配置文件,以提高运行效率。
- 数据备份: 定期备份您的数据,以防止意外丢失。
- 安全性: 确保您的系统和软件都是最新并且已打上所有的安全补丁。
- 文档: 记录您的配置和遇到的问题,这将有助于后续的维护和更新。
常见问题解答
1. 部署ChatGPT需要多长时间?
根据硬件配置和网络条件,完整的部署时间可能在几个小时到一天不等。
2. 我可以在没有GPU的情况下部署ChatGPT吗?
虽然可以在没有GPU的条件下部署,但性能会显著降低,强烈建议使用带有现代GPU的电脑。
3. 为什么我的ChatGPT模型运行速度很慢?
运行速度慢可能是由于硬件性能不足,或没有进行适当的优化。检查您的配置文件,确保已进行最佳设置。
4. 如何处理模型更新?
定期检查OpenAI的更新通知,并及时下载和安装最新版本的模型。
5. 部署过程中遇到错误该怎么办?
如果遇到错误,可以查阅官方文档或访问开发者社区寻求帮助。Stack Overflow和GitHub都是不错的求助平台。
总结
通过本地部署ChatGPT,您不仅能够更好地保护数据隐私,还可以根据需求进行个性化定制。本文为您详细介绍了部署的每一步骤,并提供了一些实用的小技巧,希望能帮助您顺利完成部署。现在,您可以开始行动,体验本地部署ChatGPT的强大功能了!如果您在过程中遇到问题,随时参考这篇指南或寻求在线帮助。