揭秘从GPT-1到GPT-4:详解GPT系列大模型的演变与技术参数
揭秘从GPT-1到GPT-4:详解GPT系列大模型的演变与技术参数
大家好!今天我们要聊的是一个非常有趣的话题——从GPT-1到GPT-4,我们要看看这些GPT系列模型是如何演变的,以及每一代模型有哪些技术参数的变化。GPT(生成式预训练转换器)已经成为改变AI领域的一个重要力量,了解它的发展历程有助于我们更好地理解未来AI的走向。
从GPT-1到GPT-4的演变
首先,我们要从GPT-1说起。GPT-1是在2018年由OpenAI发布的,它是第一个使用Transformer结构的模型。这个模型通过在大量的文本数据上进行预训练,然后通过少量的监督学习,能够生成非常流畅的文本。
GPT-2则是在2019年推出的。与GPT-1相比,它最大的进步在于参数量的增加。GPT-2的参数量达到了15亿,而GPT-1只有1.1亿。这使得GPT-2生成的文本更加自然、智能。
GPT-3的出现则是在2020年。这个版本的参数量增加到了1750亿!想象一下,这相当于把以前的模型“喂养”了更多的“知识”,因此它可以完成更多的复杂任务,比如写文章、编程。
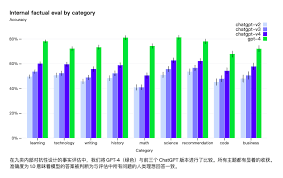
最后,GPT-4,这是最强大的版本,它不仅在参数量上更大,还具有图文双模态的特点。这意味着,GPT-4可以不仅仅处理文本,还能处理图像,进一步扩展了其应用范围。
GPT-3.5和GPT-4的区别
有人可能会问,GPT-3.5和GPT-4到底有什么区别呢?简单来说,GPT-3.5可以被看作为GPT-3的一个升级版,但它的参数量和总体架构变化不大。而GPT-4则是一次真正的大升级。
– 参数量:GPT-4比GPT-3.5多了很多参数,这意味着它有更多的“智力”去处理复杂任务。
– 模型结构:GPT-4的结构更加复杂和灵活,可以处理更多类型的数据,包括文本和图像。
– 训练数据:GPT-4使用了更大规模、更高质量的训练数据,因此它能生成更加准确和有用的输出。
– 能力:由于训练数据和模型结构的改进,GPT-4在理解和生成方面都超越了上述的版本。
GPT-4的特点和应用
作为目前最先进的版本,GPT-4有哪些独特的特点呢?
- 图文双模:不仅能处理文本信息,还能理解和生成图像。
- 更强的理解与生成能力:更高的参数量让它在处理复杂任务时如鱼得水。
- 多任务处理:可以同时处理多个任务,如翻译、问答、文章生成等。
这些特点使得GPT-4在多个领域都有广泛的应用:
- 医疗诊断:通过分析医疗数据,它可以提供辅助诊断建议。
- 教育:可用来生成教育内容,辅助教学。
- 客服:提供智能化的客户服务,解决用户问题。
实用技巧
如果你想更好地利用GPT-4,这里有一些实用的小技巧:
- 明确任务:在输入问题时,描述清楚你的需求,有助于得到更准确的答案。
- 利用提示词:使用特定的提示词可以引导模型生成更相关的内容。
- 反复调整:如果第一次结果不理想,不妨尝试不同的提示,模型会不断学习和调整。
常见问题解答
问:GPT-4的参数量到底有多大?
答:GPT-4的参数量比GPT-3多了很多,是目前最强大的版本。
问:GPT-4和GPT-3.5的主要区别是什么?
答:主要在于参数量、模型结构、训练数据和能力上都有显著提升。
问:如何使用GPT-4处理图像数据?
答:你可以通过特定的API接口将图像数据输入模型,GPT-4会进行相应的分析和处理。
问:GPT-4的应用范围有哪些?
答:涵盖了医疗、教育、客户服务等多个领域。
总结
通过对从GPT-1到GPT-4的演变进行简单回顾,我们可以看到人工智能技术的飞速发展。这些大模型不仅在参数量上有了巨大的提升,在实际应用中也展现出了强大的实力。了解这些模型的演变和技术参数,可以帮助我们更好地掌握和利用这些先进的工具,让我们的工作和生活更加智能化。
如果你对这篇文章感兴趣,想要了解更多关于GPT模型的信息,欢迎随时与我交流!